ești blocat în trecut? Încă mai folosiți paradigma Extract, Transform, Load (ETL) lentă și de modă veche pentru a procesa datele? Doriți să existe metode mai simple și mai rapide acolo?ei bine, nu mai doresc! În acest articol, vă vom arăta cum să implementați două dintre cele mai avansate tehnici de gestionare a datelor care oferă câștiguri uriașe de timp, bani și eficiență față de modelul tradițional de extragere, transformare, Încărcare.,o astfel de metodă este procesarea în flux care vă permite să vă ocupați de date în timp real din mers. Cealaltă este gestionarea automată a datelor care ocolește ETL tradițional și utilizează paradigma Extract, Load, Transform (ELT). Pentru prima, vom folosi Kafka, iar pentru cea de-a doua, vom folosi platforma de gestionare a datelor Panoply.
dar, mai întâi, să vă oferim un punct de referință cu care să lucrați: procesul convențional și greoi de încărcare a transformării extrasului.
ce este ETL (Extract Transform Load)?,
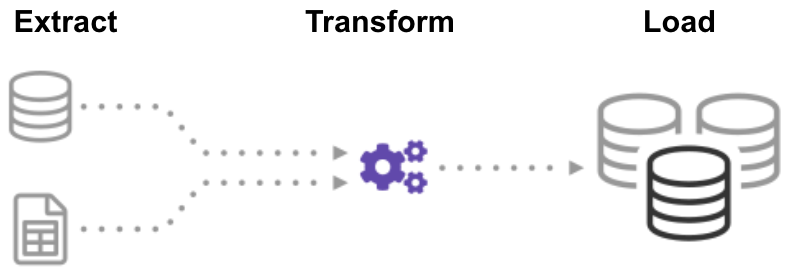
ETL (Extract, Transform, Load) este un proces automat care are date brute, extrage informațiile necesare pentru analiză, transformă-l într-un format care poate servi nevoile de afaceri, și încarcă-l la un depozit de date. ETL rezumă de obicei datele pentru a reduce dimensiunea și pentru a îmbunătăți performanța pentru anumite tipuri de analize.când construiți o infrastructură ETL, trebuie mai întâi să integrați date dintr-o varietate de surse. Apoi, trebuie să planificați și să testați cu atenție pentru a vă asigura că transformați corect datele. Acest proces este complicat și consumator de timp.,
să începem prin a analiza cum să facem acest lucru în mod tradițional: procesarea lotului.
construirea unei conducte ETL cu procesare pe loturi
într-o conductă tradițională ETL, procesați datele în loturi din bazele de date sursă într-un depozit de date. Este dificil să construiți de la zero un flux de lucru ETL pentru întreprinderi, astfel încât să vă bazați de obicei pe Instrumente ETL, cum ar fi Stitch sau Blendo, care simplifică și automatizează o mare parte a procesului.,
pentru a construi o conductă ETL cu procesare pe loturi, trebuie să:
- creați date de referință: creați un set de date care definește setul de valori admise pe care datele dvs. le pot conține. De exemplu, într-un câmp de date de țară, specificați lista codurilor de țară permise.
- extrageți date din diferite surse: baza pentru succesul pașilor ETL ulteriori este extragerea corectă a datelor. Luați date dintr-o serie de surse, cum ar fi API-uri, baze de date non/relaționale, fișiere XML, json, CSV și convertiți-le într-un singur format pentru procesare standardizată.,
- validați datele: păstrați datele care au valori în intervalele așteptate și respingeți orice nu. De exemplu, dacă doriți doar date din ultimul an, respingeți orice valori mai vechi de 12 luni. Analizați înregistrările respinse, în mod continuu, pentru a identifica problemele, a corecta datele sursă și a modifica procesul de extracție pentru a rezolva problema în loturile viitoare.
- transformarea datelor: eliminați datele duplicate( curățare), aplicați regulile de afaceri, verificați integritatea datelor (asigurați-vă că datele nu au fost corupte sau pierdute) și creați agregate după cum este necesar., De exemplu, dacă doriți să analizați veniturile, puteți rezuma suma facturilor în dolari într-un total zilnic sau lunar. Trebuie să programați numeroase funcții pentru a transforma automat datele.
- date de etapă: nu încărcați de obicei datele transformate direct în depozitul de date țintă. În schimb, datele intră mai întâi într-o bază de date de așteptare, ceea ce face mai ușor să se întoarcă dacă ceva nu merge bine. În acest moment, puteți genera, de asemenea, rapoarte de audit pentru respectarea reglementărilor sau puteți diagnostica și repara problemele legate de date.,
- publicați în depozitul de date: încărcați datele în tabelele țintă. Unele depozite de date suprascriu informațiile existente ori de câte ori conducta ETL Încarcă un lot nou – acest lucru se poate întâmpla zilnic, săptămânal sau lunar. În alte cazuri, fluxul de lucru ETL poate adăuga date fără suprascriere, inclusiv o marcă de timp pentru a indica faptul că este nou. Trebuie să faceți acest lucru cu atenție pentru a împiedica depozitul de date să „explodeze” din cauza spațiului pe disc și a limitărilor de performanță.,
construirea unei conducte ETL cu procesare în flux
procesele moderne de date includ adesea date în timp real, cum ar fi date de analiză web de pe un site mare de comerț electronic. În aceste cazuri, nu puteți extrage și transforma datele în loturi mari, ci, în schimb, trebuie să efectuați ETL pe fluxurile de date. Astfel, pe măsură ce aplicațiile client scriu date către sursa de date, trebuie să le curățați și să le transformați în timp ce sunt în tranzit către magazinul de date țintă.multe instrumente de procesare a fluxului sunt disponibile astăzi – inclusiv Apache Samza, Apache Storm și Apache Kafka., Diagrama de mai jos ilustrează un ETL conducte bazat pe Kafka, descris de Confluente:
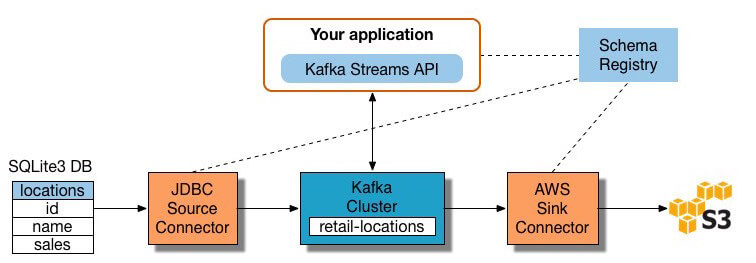
Sursa Imaginii
Pentru a construi un flux de procesare ETL conducte cu Kafka, aveți nevoie pentru a:
- Extract de date în Kafka: Confluente JDBC conector trage fiecare rând din sursa de masă și scrie-l ca o cheie/valoare pereche într-un Kafka subiect (o alimentare în cazul în care înregistrările sunt stocate și publicate). Aplicațiile interesate de starea acestui tabel citesc din acest subiect., Pe măsură ce aplicațiile client adaugă rânduri în tabelul sursă, Kafka le scrie automat ca mesaje noi la subiectul Kafka, permițând un flux de date în timp real. Notă puteți implementa o conexiune bază de date-te fără produsul comercial Confluent lui.
- trageți date din subiectele Kafka: aplicația ETL extrage mesaje din subiectul Kafka ca înregistrări Avro, creează un fișier schemă Avro și le deserializează. Apoi creează obiecte KStream din mesaje.,
- transformă datele în obiecte KStream: cu API-ul Kafka Streams, procesorul de flux primește câte o înregistrare, o procesează și produce una sau mai multe înregistrări de ieșire pentru procesoarele din aval. Aceste procesoare pot transforma mesajele pe rând, le pot filtra în funcție de condiții și pot efectua operațiuni de date pe mai multe mesaje, cum ar fi agregarea.
- încărcați datele către alte sisteme: aplicația ETL deține în continuare datele îmbogățite și acum trebuie să le transmită în sisteme țintă, cum ar fi un depozit de date sau un lac de date., În exemplul lui Confluent, ei propun utilizarea conectorului de chiuvetă S3 pentru a transmite datele către Amazon S3. De asemenea, puteți integra cu alte sisteme, cum ar fi un depozit de date Redshift folosind Amazon Kinesis.acum știți cum să efectuați procesele ETL în mod tradițional și pentru transmiterea datelor. Să ne uităm la procesul care revoluționează prelucrarea datelor: Extract Load Transform.
ce este ELT (Extract Load Transform)?,
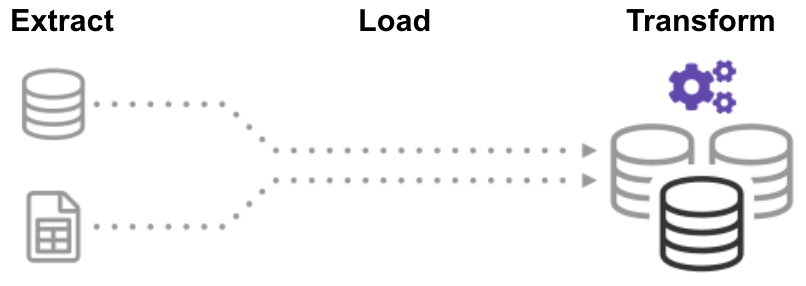
Extractul de Încărcare Transforma (ELT) proces, primul extras datele, și apoi trece imediat într-un depozit de date centralizate. După aceea, datele sunt transformate după cum este necesar pentru utilizarea în aval. Această metodă obține date în fața analiștilor mult mai rapid decât ETL, simplificând simultan arhitectura.mai mult decât atât, astăzi cloud data warehouse și data lake infrastructura suport amplu de stocare și putere de calcul scalabile., Astfel, nu mai este necesar să împiedicăm depozitul de date să” explodeze ” prin păstrarea datelor mici și rezumate prin transformări înainte de încărcare. Este posibil să mențineți grupuri masive de date în cloud la un cost redus, în timp ce utilizați instrumentele ELT pentru a accelera și simplifica procesarea datelor.
ELT poate suna prea frumos pentru a fi adevărat, dar ai încredere în noi, nu este! Să construim acum o conductă ELT automatizată.,
construirea unei conducte fără ETL folosind un depozit automat de date Cloud
noua tehnologie cloud data warehouse face posibilă atingerea obiectivului ETL inițial fără a construi deloc un sistem ETL.
de exemplu, depozitul automatizat de date Cloud Panoply are integrat un management de date end-to-end. Utilizează o arhitectură de auto-optimizare, care extrage și transformă automat datele pentru a se potrivi cerințelor de analiză., Panoply are peste 80 integrări sursă de date native, inclusiv MRC, sisteme de analiză, baze de date, platforme sociale și de publicitate, și se conectează la toate instrumentele BI majore și notebook-uri analitice.pentru a construi o conductă de date fără ETL în Panoply, trebuie să:
-
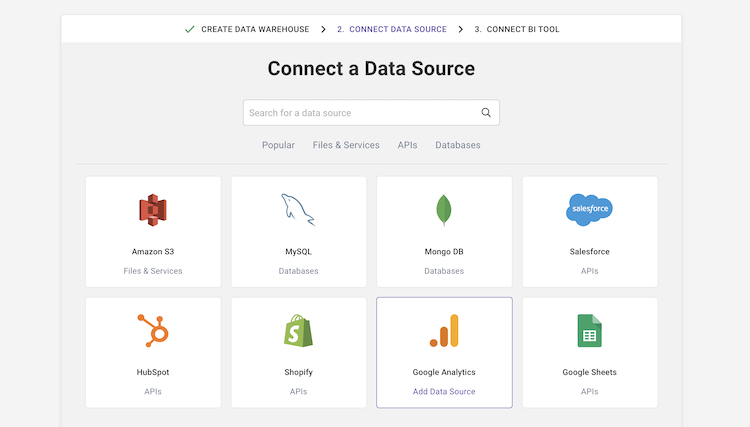
selectați Surse de date și importați date: selectați Surse de date dintr-o listă, introduceți acreditările și definiți tabelele de destinație. Faceți clic pe” colectați ” și Panoply trage automat datele pentru dvs. Panoply are grijă automat de scheme, pregătirea datelor, curățarea datelor și multe altele.,
- rulați interogări de transformare: selectați un tabel și rulați o interogare SQL împotriva datelor brute. Puteți salva interogarea ca transformare sau exporta tabelul rezultat ca CSV. Puteți rula mai multe transformări până când obțineți formatul de date de care aveți nevoie. Nu ar trebui să vă preocupați de „ruinarea” datelor – Panoply vă permite să efectuați orice transformare, dar vă păstrează intacte datele brute.
- efectuați analiza datelor cu instrumente BI: acum Puteți conecta orice instrument BI, cum ar fi Tableau sau Looker, pentru a panoplia și a explora datele transformate.,procesul de mai sus este agil și flexibil, permițându-vă să încărcați rapid datele, să le transformați într-o formă utilă și să efectuați analize. Pentru mai multe detalii, consultați Noțiuni de bază cu Panoply.
cu Vechiul, cu Noi
știi acum trei moduri de a construi un Extras Transforma procesul de Încărcare, care vă puteți gândi ca la trei stadii în evoluția ETL:
- ETL Tradițională de prelucrare a lot – meticulozitate pregătirea și transformarea datelor folosind un rigid, proces structurat.,
- ETL cu procesarea fluxului-folosind un cadru modern de procesare a fluxului precum Kafka, trageți date în timp real de la sursă, manipulați-le din mers folosind API-ul fluxului Kafka și încărcați-l într-un sistem țintă, cum ar fi Amazon Redshift.
- Automated data pipeline without ETL – utilizați conducte de date automate Panoply lui, pentru a trage date din mai multe surse, în mod automat prep-l fără a necesita un proces complet ETL, și începe imediat analiza folosind instrumentele BI preferate. Începeți cu panoplia în câteva minute.,ETL tradițional funcționează, dar este lent și rapid devenind învechit. Dacă doriți ca compania dvs. să maximizeze valoarea pe care o extrage din datele sale, este timpul pentru un nou flux de lucru ETL.Panoply este un loc sigur pentru a stoca, sincroniza și accesa toate datele dvs. de afaceri. Panoply poate fi configurat în câteva minute, necesită întreținere continuă zero și oferă suport online, inclusiv acces la arhitecți de date cu experiență. Încercați Panoply gratuit timp de 14 zile.
-




