Sei bloccato nel passato? Stai ancora usando il paradigma Extract, Transform, Load (ETL) lento e vecchio stile per elaborare i dati? Ti piacerebbe che ci fossero metodi più semplici e più veloci là fuori?
Bene, non desiderare più! In questo articolo, ti mostreremo come implementare due delle tecniche di gestione dei dati più all’avanguardia che forniscono enormi guadagni di tempo, denaro e efficienza rispetto al tradizionale modello di estrazione, trasformazione e carico.,
Uno di questi metodi è l’elaborazione del flusso che consente di gestire i dati in tempo reale al volo. L’altro è la gestione automatizzata dei dati che bypassa l’ETL tradizionale e utilizza il paradigma Extract, Load, Transform (ELT). Per il primo, useremo Kafka, e per il secondo, useremo la piattaforma di gestione dei dati di Panoply.
Ma prima, ti diamo un benchmark con cui lavorare: il convenzionale e ingombrante processo di caricamento di trasformazione dell’estratto.
Che cos’è ETL (Extract Transform Load)?,
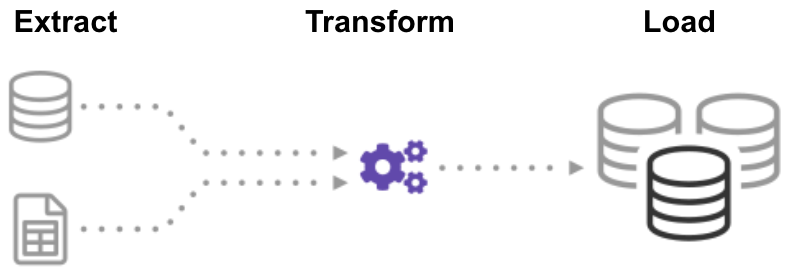
ETL (Extract, Transform, Load) è un processo automatizzato che prende dati grezzi, estrae le informazioni necessarie per l’analisi, le trasforma in un formato in grado di soddisfare le esigenze aziendali e le carica in un data warehouse. ETL in genere riassume i dati per ridurne le dimensioni e migliorare le prestazioni per specifici tipi di analisi.
Quando si crea un’infrastruttura ETL, è necessario prima integrare i dati da una varietà di fonti. Quindi è necessario pianificare e testare attentamente per assicurarsi di trasformare correttamente i dati. Questo processo è complicato e richiede molto tempo.,
Iniziamo osservando come farlo nel modo tradizionale: elaborazione batch.
Creazione di una pipeline ETL con elaborazione batch
In una pipeline ETL tradizionale, si elaborano i dati in batch dai database di origine a un data warehouse. È difficile creare un flusso di lavoro ETL aziendale da zero, quindi in genere ci si affida a strumenti ETL come Stitch o Blendo, che semplificano e automatizzano gran parte del processo.,
Per creare una pipeline ETL con elaborazione batch, è necessario:
- Creare dati di riferimento: creare un set di dati che definisca l’insieme di valori consentiti che i dati possono contenere. Ad esempio, in un campo Dati paese, specificare l’elenco dei codici paese consentiti.
- Estrarre dati da diverse fonti: la base per il successo dei passaggi ETL successivi è estrarre i dati correttamente. Prendi i dati da una serie di fonti, come API, database non/relazionali, file XML, JSON, CSV e convertili in un unico formato per l’elaborazione standardizzata.,
- Convalida dati: conserva i dati che hanno valori negli intervalli previsti e rifiuta quelli che non lo fanno. Ad esempio, se si desidera solo date dell’ultimo anno, rifiutare qualsiasi valore superiore a 12 mesi. Analizzare i record rifiutati, su base continuativa, per identificare i problemi, correggere i dati di origine e modificare il processo di estrazione per risolvere il problema in batch futuri.
- Trasforma i dati: rimuovi i dati duplicati( pulizia), applica le regole aziendali, controlla l’integrità dei dati (assicurati che i dati non siano stati danneggiati o persi) e crea aggregati se necessario., Ad esempio, se si desidera analizzare le entrate, è possibile riassumere l’importo in dollari delle fatture in un totale giornaliero o mensile. È necessario programmare numerose funzioni per trasformare automaticamente i dati.
- Dati di fase: in genere non si caricano i dati trasformati direttamente nel data warehouse di destinazione. Invece, i dati entrano prima in un database di staging che rende più facile il rollback se qualcosa va storto. A questo punto, è anche possibile generare report di controllo per la conformità alle normative, o diagnosticare e riparare i problemi di dati.,
- Pubblica nel data warehouse: carica i dati nelle tabelle di destinazione. Alcuni data warehouse sovrascrivono le informazioni esistenti ogni volta che la pipeline ETL carica un nuovo batch: ciò potrebbe accadere giornalmente, settimanalmente o mensilmente. In altri casi, il flusso di lavoro ETL può aggiungere dati senza sovrascrivere, incluso un timestamp per indicare che è nuovo. È necessario eseguire questa operazione con attenzione per evitare che il data warehouse “esploda” a causa di limitazioni di spazio su disco e prestazioni.,
Creazione di una pipeline ETL con elaborazione del flusso
I moderni processi di dati spesso includono dati in tempo reale, come i dati di analisi Web di un grande sito di e-commerce. In questi casi, non è possibile estrarre e trasformare i dati in batch di grandi dimensioni, ma è necessario eseguire ETL sui flussi di dati. Pertanto, poiché le applicazioni client scrivono i dati nell’origine dati, è necessario pulirli e trasformarli mentre sono in transito nell’archivio dati di destinazione.
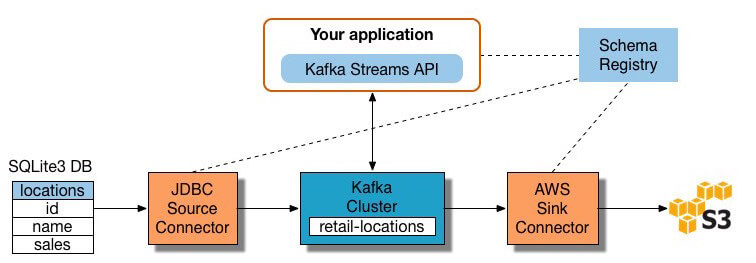
Oggi sono disponibili molti strumenti di elaborazione del flusso, tra cui Apache Samza, Apache Storm e Apache Kafka., Il diagramma riportato di seguito viene illustrato un ETL pipeline basata su Kafka, descritto da Confluenti:
Fonte dell’Immagine
costruire un flusso di elaborazione ETL pipeline con Kafka, hai bisogno di:
- Estrarre i dati in Kafka: Confluenti connettore JDBC tira ogni riga della tabella di origine e scrive come una coppia chiave/valore in un Kafka argomento (un feed in cui sono archiviati e pubblicati). Le applicazioni interessate allo stato di questa tabella leggono da questo argomento., Quando le applicazioni client aggiungono righe alla tabella di origine, Kafka le scrive automaticamente come nuovi messaggi nell’argomento Kafka, consentendo un flusso di dati in tempo reale. Nota è possibile implementare una connessione al database da soli senza il prodotto commerciale di Confluent.
- Estrarre i dati dagli argomenti Kafka: l’applicazione ETL estrae i messaggi dall’argomento Kafka come record Avro, crea un file di schema Avro e li deserializza. Quindi crea oggetti KStream dai messaggi.,
- Trasforma i dati in oggetti KStream: con l’API Kafka Streams, il processore stream riceve un record alla volta, lo elabora e produce uno o più record di output per i processori downstream. Questi processori possono trasformare i messaggi uno alla volta, filtrarli in base alle condizioni ed eseguire operazioni di dati su più messaggi, ad esempio l’aggregazione.
- Carica i dati su altri sistemi: l’applicazione ETL conserva ancora i dati arricchiti e ora deve trasmetterli in streaming nei sistemi di destinazione, come un data warehouse o un data lake., Nell’esempio di Confluent, propongono di utilizzare il connettore Sink S3 per lo streaming dei dati su Amazon S3. Puoi anche integrarti con altri sistemi, ad esempio un data warehouse Redshift, utilizzando Amazon Kinesis.
Ora sai come eseguire i processi ETL in modo tradizionale e per lo streaming dei dati. Diamo un’occhiata al processo che sta rivoluzionando l’elaborazione dei dati: Extract Load Transform.
Che cos’è ELT (Extract Load Transform)?,
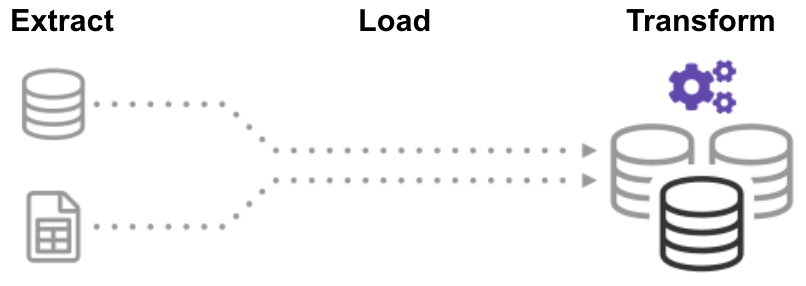
Nel processo ELT (Extract Load Transform), estrai prima i dati e poi li sposti immediatamente in un repository di dati centralizzato. Successivamente, i dati vengono trasformati secondo necessità per l’uso a valle. Questo metodo ottiene i dati di fronte agli analisti molto più velocemente di ETL e contemporaneamente semplifica l’architettura.
Inoltre, l’odierna infrastruttura cloud data warehouse e data lake supporta un ampio spazio di archiviazione e una potenza di calcolo scalabile., Pertanto, non è più necessario impedire che il data warehouse “esploda” mantenendo i dati piccoli e riassunti attraverso le trasformazioni prima del caricamento. È possibile mantenere enormi pool di dati nel cloud a basso costo sfruttando gli strumenti ELT per accelerare e semplificare l’elaborazione dei dati.
ELT può sembrare troppo bello per essere vero, ma fidati di noi, non lo è! Costruiamo ora una pipeline ELT automatizzata.,
Creazione di una pipeline senza ETL Utilizzando un Data Warehouse cloud automatizzato
La nuova tecnologia cloud data warehouse consente di raggiungere l’obiettivo ETL originale senza creare un sistema ETL.
Ad esempio, il data warehouse cloud automatizzato di Panoply ha una gestione dei dati end-to-end integrata. Utilizza un’architettura auto-ottimizzazione, che estrae e trasforma automaticamente i dati per soddisfare i requisiti di analisi., Panoply ha oltre 80 integrazioni di origini dati native, tra cui CRM, sistemi di analisi, database, piattaforme social e pubblicitarie, e si connette a tutti i principali strumenti di BI e notebook analitici.
Per creare una pipeline di dati senza ETL in Panoply, è necessario:
-
Selezionare origini dati e importare dati: selezionare origini dati da un elenco, inserire le credenziali e definire le tabelle di destinazione. Fai clic su “Raccogli” e Panoply estrae automaticamente i dati per te. Panoply si occupa automaticamente di schemi, preparazione dei dati, pulizia dei dati e altro ancora.,
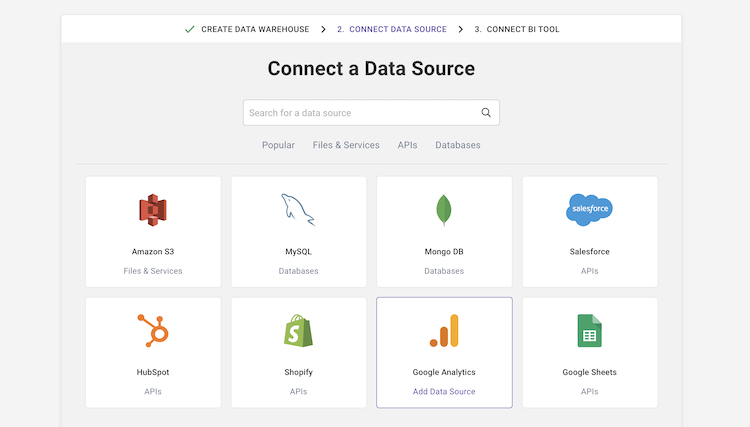
- Esegui query di trasformazione: seleziona una tabella ed esegui una query SQL sui dati grezzi. È possibile salvare la query come trasformazione o esportare la tabella risultante come CSV. È possibile eseguire diverse trasformazioni fino a raggiungere il formato di dati necessario. Non dovresti preoccuparti di “rovinare” i dati: Panoply ti consente di eseguire qualsiasi trasformazione, ma mantiene intatti i tuoi dati grezzi.
- Eseguire l’analisi dei dati con strumenti di BI: ora è possibile collegare qualsiasi strumento di BI come Tableau o Looker per Panoply ed esplorare i dati trasformati.,
Il processo di cui sopra è agile e flessibile, che consente di caricare rapidamente i dati, trasformarli in una forma utile, ed eseguire analisi. Per ulteriori dettagli, vedere Guida introduttiva a Panoply.
Fuori con il vecchio, dentro con il nuovo
Ora conosci tre modi per costruire un processo di carico di trasformazione estratto, che puoi pensare a tre fasi nell’evoluzione di ETL:
- Elaborazione batch ETL tradizionale – preparazione e trasformazione meticolosa dei dati utilizzando un processo rigido e strutturato.,
- ETL con l’elaborazione del flusso-utilizzando un moderno framework di elaborazione del flusso come Kafka, estrai i dati in tempo reale dall’origine, li manipoli al volo usando l’API Stream di Kafka e li carichi su un sistema di destinazione come Amazon Redshift.
- Pipeline di dati automatizzata senza ETL-usa le pipeline di dati automatizzate di Panoply, per estrarre dati da più fonti, prepararli automaticamente senza richiedere un processo ETL completo e iniziare immediatamente ad analizzarli utilizzando i tuoi strumenti di BI preferiti. Inizia con Panoply in pochi minuti.,
L’ETL tradizionale funziona, ma è lento e veloce diventando obsoleto. Se vuoi che la tua azienda massimizzi il valore che estrae dai suoi dati, è il momento di un nuovo flusso di lavoro ETL.
Panoply è un luogo sicuro per archiviare, sincronizzare e accedere a tutti i dati aziendali. Panoply può essere impostato in pochi minuti, richiede zero manutenzione in corso e fornisce supporto online, incluso l’accesso a data architect esperti. Prova Panoply gratis per 14 giorni.




