Você está preso no passado? Você ainda está usando o extrato lento e antiquado, transformar, carregar (ETL) paradigma para processar dados? Gostavas que houvesse métodos mais simples e mais rápidos?bem, não desejes mais! Neste artigo, vamos mostrar-lhe como implementar duas das mais modernas técnicas de gerenciamento de dados que proporcionam enormes ganhos de tempo, dinheiro e eficiência sobre o modelo tradicional de extração, transformação, carga.,
um desses métodos é o processamento de fluxo que lhe permite lidar com dados em tempo real na mosca. A outra é a gestão automatizada de dados que contorna o ETL tradicional e usa o paradigma Extract, Load, Transform (ELT). Para o primeiro, usaremos Kafka, e para o segundo, usaremos a plataforma de gerenciamento de dados da Panoply.
mas primeiro, vamos dar – lhe uma referência para trabalhar com: o processo convencional e pesado de extração de transformação de carga.o que é o ETL (Extract Transform Load)?,
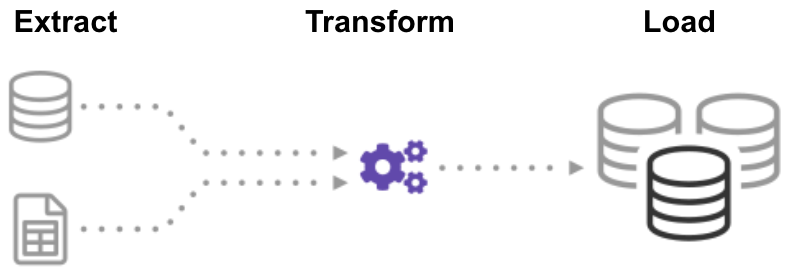
ETL (Extract, Transform, Load) é um processo automatizado que leva dados brutos, extrai as informações necessárias para a análise, transforma-lo em um formato que pode servir as necessidades do negócio, e carrega-lo para um armazém de dados. O ETL geralmente resume dados para reduzir seu tamanho e melhorar o desempenho para tipos específicos de análise.
Quando você constrói uma infra-estrutura ETL, você deve primeiro integrar dados de uma variedade de fontes. Então você deve planejar cuidadosamente e testar para garantir que você transforma os dados corretamente. Este processo é complicado e demorado.,
vamos começar por ver como fazer isso da maneira tradicional: processamento em lote.
construindo um oleoduto ETL com processamento em lote
em um oleoduto ETL tradicional, você processa dados em lotes de bases de dados fonte para um armazém de dados. É um desafio construir um fluxo de trabalho de ETL da empresa a partir do zero, então você normalmente confia em ferramentas de ETL, como Stitch ou Blendo, que simplificam e automatizam grande parte do processo.,
para construir uma conduta ETL com processamento em lote, você precisa:
- Criar dados de referência: criar um conjunto de dados que define o conjunto de valores admissíveis que os seus dados podem conter. Por exemplo, em um campo de dados de país, especifique a lista de códigos de país permitidos.extrair dados de diferentes fontes: a base para o sucesso das etapas ETL subsequentes é extrair dados corretamente. Pegar dados de uma série de fontes, tais como APIs, bases de dados não relacionais, XML, JSON, arquivos CSV, e convertê-lo em um único formato para processamento padronizado.,
- validar dados: Mantenha os dados que têm valores nos intervalos esperados e rejeite os que não têm. Por exemplo, se você só quiser datas do último ano, rejeite quaisquer valores com mais de 12 meses. Analisar registros rejeitados, em uma base contínua, para identificar problemas, corrigir os dados de origem, e modificar o processo de extração para resolver o problema em futuros lotes.
- transformar dados: remover dados duplicados (limpeza), aplicar regras de Negócio, verificar a integridade dos dados (garantir que os dados não foram corrompidos ou perdidos), e criar agregados, conforme necessário., Por exemplo, se você quiser analisar a receita, você pode resumir a quantidade de dólares de faturas em um total diário ou mensal. Você precisa programar várias funções para transformar os dados automaticamente.
- dados de fase: normalmente não carrega dados transformados directamente no armazém de dados de destino. Em vez disso, os dados entram primeiro em uma base de dados de staging que torna mais fácil de rolar para trás se algo corre mal. Neste ponto, você também pode gerar relatórios de auditoria para a conformidade regulamentar, ou diagnosticar e reparar problemas de dados.,publique no seu armazém de dados: carregue os dados para as tabelas-alvo. Alguns armazéns de dados sobrepõem a informação existente sempre que o gasoduto ETL carrega um novo lote – isso pode acontecer diariamente, semanalmente ou mensalmente. Em outros casos, o fluxo de trabalho ETL pode adicionar dados sem substituição, incluindo um timestamp para indicar que é novo. Você deve fazer isso com cuidado para evitar que o data warehouse de “explodir” devido ao espaço em disco e limitações de desempenho.,
construir um oleoduto ETL com processamento de fluxo
os processos de dados modernos muitas vezes incluem dados em tempo real, tais como dados de análise web de um grande site de E-commerce. Nestes casos, você não pode extrair e transformar dados em grandes lotes, mas em vez disso, precisa executar ETL em fluxos de dados. Assim, enquanto as aplicações clientes escrevem dados para a fonte de dados, você precisa limpá-lo e transformá-lo enquanto ele está em trânsito para a loja de dados alvo.
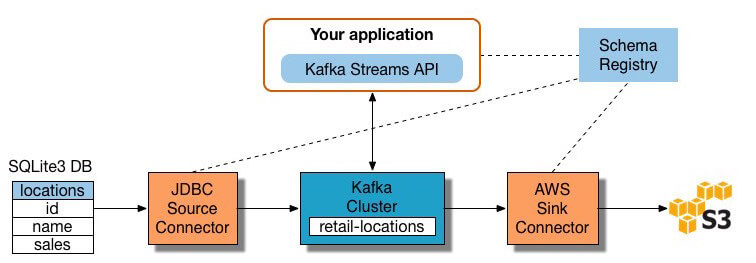
muitas ferramentas de processamento de fluxo estão disponíveis hoje-incluindo Apache Samza, Apache Storm, E Apache Kafka., O diagrama abaixo ilustra um ETL pipeline com base em Kafka, descrito por Confluente:
Fonte da Imagem
Para criar um fluxo de processamento do ETL pipeline com Kafka, você precisa:
- Extrair dados em Kafka: Confluente JDBC conector puxa cada linha da tabela de origem e grava-a como um par chave/valor em uma Kafka tópico (um feed onde os registros são armazenados e publicado). Aplicações interessadas no estado desta tabela leia a partir deste tópico., À medida que as aplicações cliente adicionam linhas à tabela de código, o Kafka escreve-as automaticamente como novas mensagens para o tópico do Kafka, activando um fluxo de dados em tempo real. Note que você pode implementar uma conexão de banco de dados sem Produto Comercial do Confluente.a aplicação ETL extrai mensagens do tópico Kafka como registros Avro, cria um arquivo Avro schema, e deserializa-os. Então ele cria objetos KStream a partir das mensagens.,
- Transforme dados em objetos KStream: com a API de fluxo de Kafka, o processador de fluxo recebe um registro de cada vez, processa-o, e produz um ou mais registros de saída para processadores a jusante. Estes processadores podem transformar mensagens um de cada vez, filtrá-las com base em condições, e realizar operações de dados em múltiplas mensagens, tais como agregação.dados de carga para outros sistemas: a aplicação ETL ainda contém os dados enriquecidos, e agora precisa transportá-los para sistemas-alvo, como um armazém de dados ou um lago de dados., No exemplo do Confluente, eles propõem usar seu conector S3 Sink para transmitir os dados para Amazon S3. Você também pode se integrar com outros sistemas, como um armazém de dados Redshift usando a Amazon Kinesis.
Agora você sabe como executar os processos ETL da maneira tradicional e para streaming de dados. Vamos olhar para o processo que está revolucionando o processamento de dados: extrair a transformação de carga.o que é o ELT (Extract Load Transform)?,
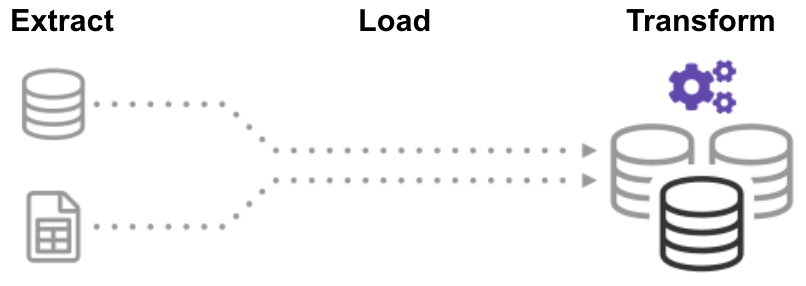
no processo de transformação de carga de extração (ELT), você primeiro extrai os dados, e então você imediatamente movê-los para um repositório de dados centralizado. Depois disso, os dados são transformados conforme necessário para a utilização a jusante. Este método recebe dados na frente dos analistas muito mais rápido do que o ETL, simplificando simultaneamente a arquitetura.
além disso, o armazenamento de dados na nuvem e a infraestrutura do lago de dados de hoje suportam amplo armazenamento e poder computacional escalável., Assim, não é mais necessário impedir que o armazém de dados “expluda”, mantendo os dados pequenos e resumidos através de transformações antes do Carregamento. É possível manter grandes reservas de dados na nuvem a um baixo custo, ao mesmo tempo em que alavancam as ferramentas ELT para acelerar e simplificar o processamento de dados.
ELT pode soar muito bom para ser verdade, mas acredite em nós, não é! Vamos construir um oleoduto automático ELT agora.,a nova tecnologia cloud data warehouse permite atingir o objectivo original da ETL sem construir um sistema ETL.
Por exemplo, o armazém automatizado de dados em nuvem da Panoply tem o gerenciamento de dados de ponta a ponta embutido. Ele usa uma arquitetura de auto-otimização, que automaticamente extrai e transforma dados para corresponder aos requisitos de análise., Panoply tem mais de 80 integrações de fontes de dados nativas, incluindo CRMs, sistemas de análise, bases de dados, plataformas sociais e de publicidade, e se conecta a todas as principais ferramentas BI e Cadernos analíticos.
para construir um pipeline de dados sem ETL em panóplia, você precisa:
-
selecione Fontes de dados e importação de dados: selecione Fontes de dados de uma lista, insira suas credenciais e defina tabelas de destino. Clique em “coletar”, e Panoply automaticamente puxa os dados para você. Panoply automaticamente cuida dos esquemas, preparação de dados, Limpeza de dados, e muito mais.,
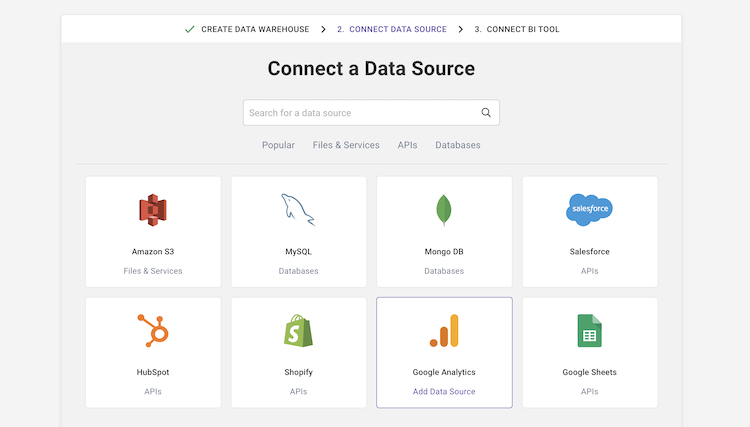
- procura de transformação de execução: seleccione uma tabela e execute uma pesquisa SQL com os dados brutos. Você pode salvar a consulta como uma transformação, ou exportar a tabela resultante como um CSV. Você pode executar várias transformações até que você alcance o formato de dados que você precisa. Você não deve se preocupar em” arruinar ” os dados – Panoply permite que você realize qualquer transformação, mas mantém seus dados brutos intactos.
- execute a análise de dados com ferramentas BI: você pode agora conectar qualquer ferramenta BI, como Tableau ou Looker para Panoply e explorar os dados transformados.,
o processo acima é ágil e flexível, permitindo-lhe carregar rapidamente dados, transformá-los em uma forma útil, e realizar análises. Para mais detalhes, veja começar com Panoply.
Fora com o Velho, com o Novo
agora Você já sabe três formas para construir uma Extract Transform Load processo, que você pode pensar como se três fases na evolução da ETL:
- Tradicional ETL processamento em lote – meticulosa preparação e transformação de dados através de uma rígida, estruturada processo.,
- ETL com processamento de fluxo-usando uma estrutura de processamento de fluxo moderna como o Kafka, você puxa os dados em tempo real da fonte, manipula-os em tempo real usando a API de fluxo do Kafka, e carrega-os para um sistema de destino como o Redshift Amazon.
- pipeline automatizado de dados sem ETL-use pipelines automatizados de dados da Panoply, para extrair dados de várias fontes, prepará-lo automaticamente sem exigir um processo ETL completo, e imediatamente começar a analisá-lo usando suas ferramentas BI favoritas. Começa com Panoply em minutos.,
trabalhos ETL tradicionais, mas é lento e rápido se tornando obsoleto. Se você quer que sua empresa para maximizar o valor que extrai de seus dados, é hora de um novo fluxo de trabalho ETL.
Panoply é um lugar seguro para armazenar, sincronizar e acessar todos os seus dados de negócios. A Panoply pode ser configurada em minutos, requer zero manutenção em andamento, e fornece suporte on-line, incluindo acesso a arquitetos de dados experientes. Tente a Panoply livre por 14 dias.




