Êtes-vous coincé dans le passé? Utilisez-vous toujours le paradigme lent et à l’ancienne Extract, Transform, Load (ETL) pour traiter les données? Souhaitez-vous qu’il y ait des méthodes plus simples et plus rapides?
Eh bien, ne souhaite plus! Dans cet article, nous allons vous montrer comment mettre en œuvre deux des techniques de gestion de données les plus avancées qui offrent d’énormes gains de temps, d’argent et d’efficacité par rapport au modèle traditionnel D’extraction, de transformation et de chargement.,
Une de ces méthodes est le traitement de flux qui vous permet de traiter des données en temps réel à la volée. L’autre est la gestion automatisée des données qui contourne l’ETL traditionnel et utilise le paradigme ELT (Extract, Load, Transform). Pour le premier, nous utiliserons Kafka, et pour le second, Nous utiliserons la plate-forme de gestion des données de Panoply.
mais d’abord, nous allons vous donner une référence pour travailler avec: le processus de charge de transformation D’extrait classique et lourd.
qu’est-ce que L’ETL (Extract Transform Load)?,
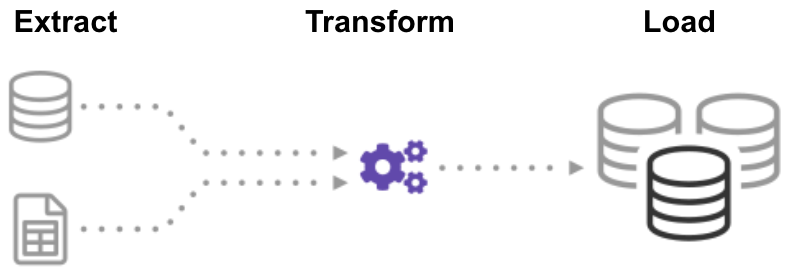
ETL (Extract, Transform, Load) est un processus automatisé qui prend des données brutes, extrait les informations nécessaires à l’analyse, les transforme en un format pouvant répondre aux besoins de l’entreprise et les charge dans un entrepôt de données. ETL résume généralement les données pour réduire leur taille et améliorer les performances pour des types d’analyse spécifiques.
lorsque vous créez une infrastructure ETL, vous devez d’abord intégrer des données provenant de diverses sources. Ensuite, vous devez soigneusement planifier et tester pour vous assurer de transformer les données correctement. Ce processus est compliqué et prend du temps.,
commençons par regarder comment faire cela de la manière traditionnelle: le traitement par lots.
construire un Pipeline ETL avec traitement par lots
Dans un pipeline ETL traditionnel, vous traitez les données par lots des bases de données source vers un entrepôt de données. Il est difficile de créer un flux de travail ETL d’entreprise à partir de zéro, de sorte que vous comptez généralement sur des outils ETL tels que Stitch ou Blendo, qui simplifient et automatisent une grande partie du processus.,
pour créer un pipeline ETL avec traitement par lots, vous devez:
- créer des données de référence: créez un ensemble de données qui définit l’ensemble des valeurs autorisées que vos données peuvent contenir. Par exemple, dans un champ de données de pays, spécifiez la liste des codes de pays autorisés.
- extraire des données de différentes sources: la base du succès des étapes ETL suivantes est d’extraire correctement les données. Prenez des données provenant d’une gamme de sources, telles que des API, des bases de données non relationnelles, des fichiers XML, JSON, CSV, et convertissez-les en un format unique pour un traitement standardisé.,
- valider les données: conservez les données qui ont des valeurs dans les plages attendues et rejetez celles qui ne le sont pas. Par exemple, si vous ne voulez que des dates de l’année dernière, rejetez toutes les valeurs de plus de 12 mois. Analysez régulièrement les enregistrements rejetés pour identifier les problèmes, corriger les données source et modifier le processus d’extraction afin de résoudre le problème dans les lots futurs.
- transformer les données: supprimer les données en double (nettoyage), appliquer des règles métier, vérifier l’intégrité des données (s’assurer que les données n’ont pas été corrompues ou perdues) et créer des agrégats si nécessaire., Par exemple, si vous souhaitez analyser les revenus, vous pouvez résumer le montant en dollars des factures en un total quotidien ou mensuel. Vous devez programmer de nombreuses fonctions pour transformer les données automatiquement.
- données D’étape: vous ne chargez généralement pas les données transformées directement dans l’entrepôt de données cible. Au lieu de cela, les données entrent d’abord dans une base de données Intermédiaire, ce qui facilite la restauration en cas de problème. À ce stade, vous pouvez également générer des rapports d’audit pour la conformité réglementaire, ou diagnostiquer et réparer les problèmes de données.,
- publier dans votre entrepôt de données: Charger les données dans les tables cibles. Certains entrepôts de données écrasent les informations existantes chaque fois que le pipeline ETL charge un nouveau lot-cela peut se produire quotidiennement, chaque semaine ou chaque mois. Dans d’autres cas, le workflow ETL peut ajouter des données sans écraser, y compris un horodatage pour indiquer qu’il est nouveau. Vous devez le faire avec soin pour éviter que l’entrepôt de données « explose » en raison des limitations d’espace disque et de performances.,
construire un Pipeline ETL avec traitement de flux
Les processus de données modernes incluent souvent des données en temps réel, telles que des données d’analyse web provenant d’un grand site Web de commerce électronique. Dans ces cas, vous ne pouvez pas extraire et transformer des données en lots volumineux, mais vous devez plutôt effectuer ETL sur des flux de données. Ainsi, lorsque les applications clientes écrivent des données dans la source de données, vous devez les nettoyer et les transformer pendant leur transit vers le magasin de données cible.
de nombreux outils de traitement de flux sont disponibles aujourd’hui, notamment Apache Samza, Apache Storm et Apache Kafka., Le diagramme ci-dessous illustre un pipeline ETL basé sur Kafka, décrit par Confluent:
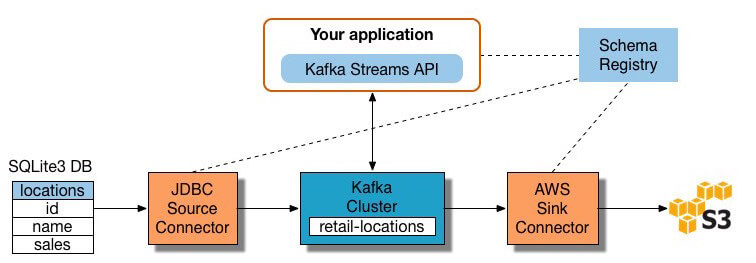
Image Source
pour construire un pipeline ETL de traitement de flux avec Kafka, vous devez:
- extraire des données dans Kafka: Le connecteur JDBC Confluent tire chaque ligne de la table source et l’écrit en tant où les enregistrements sont stockés et publiés). Les Applications intéressées par l’état de ce tableau lues à partir de ce sujet., Lorsque les applications clientes ajoutent des lignes à la table source, Kafka les écrit automatiquement sous forme de nouveaux messages dans la rubrique Kafka, ce qui permet un flux de données en temps réel. REMARQUE Vous pouvez implémenter vous-même une connexion à une base de données sans le produit commercial de Confluent.
- extraire les données des rubriques Kafka: l’application ETL extrait les messages de la rubrique Kafka en tant qu’enregistrements Avro, crée un fichier de schéma Avro et les désérialise. Ensuite, il crée des objets KStream à partir des messages.,
- transformer des données dans des objets KStream: avec L’API Kafka Streams, le processeur de flux reçoit un enregistrement à la fois, le traite et produit un ou plusieurs enregistrements de sortie pour les processeurs en aval. Ces processeurs peuvent transformer les messages un à la fois, les filtrer en fonction des conditions et effectuer des opérations de données sur plusieurs messages, telles que l’agrégation.
- charger les données vers d’autres systèmes: l’application ETL contient toujours les données enrichies et doit désormais les diffuser dans des systèmes cibles, tels qu’un entrepôt de données ou un lac de données., Dans L’exemple de Confluent, ils proposent d’utiliser leur connecteur D’évier S3 pour diffuser les données vers Amazon S3. Vous pouvez également vous intégrer à d’autres systèmes tels qu’un entrepôt de données Redshift à L’aide D’Amazon Kinesis.
Maintenant, vous savez comment effectuer des processus ETL de la manière traditionnelle et pour le streaming de données. Regardons le processus qui révolutionne le traitement des données: Extract Load Transform.
qu’est-Ce que ED (Extrait de la Charge de Transformation)?,
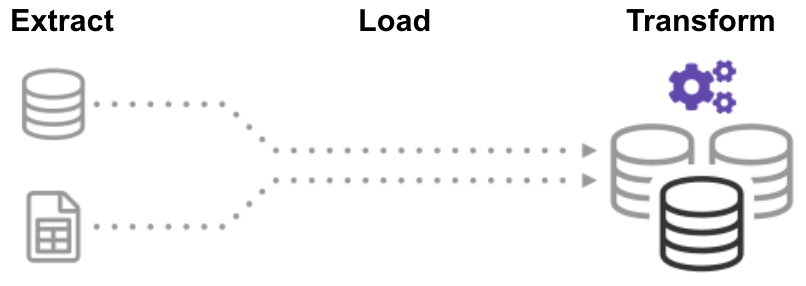
dans le processus ELT (Extract Load Transform), vous extrayez d’abord les données, puis vous les déplacez immédiatement dans un référentiel de données centralisé. Après cela, les données sont transformées selon les besoins pour une utilisation en aval. Cette méthode obtient des données devant les analystes beaucoup plus rapidement que ETL tout en simplifiant simultanément l’architecture.
de plus, l’entrepôt de données cloud et l’infrastructure de Lac de données d’aujourd’hui prennent en charge un stockage suffisant et une puissance de calcul évolutive., Ainsi, il n’est plus nécessaire d’empêcher l’entrepôt de données « d’exploser” en gardant les données petites et résumées par des transformations avant le chargement. Il est possible de maintenir des pools de données massifs dans le cloud à faible coût tout en tirant parti des outils ELT pour accélérer et simplifier le traitement des données.
ELT peut sembler trop beau pour être vrai, mais croyez-nous, ce n’est pas le cas! Construisons maintenant un pipeline ELT automatisé.,
construire un Pipeline sans ETL à l’aide d’un entrepôt de données Cloud automatisé
La nouvelle technologie d’entrepôt de données cloud permet d’atteindre l’objectif ETL initial sans créer de système ETL.
Par exemple, L’entrepôt de données cloud automatisé de Panoply intègre une gestion des données de bout en bout. Il utilise une architecture auto-optimisante, qui extrait et transforme automatiquement les données pour répondre aux exigences d’analyse., Panoply dispose de plus de 80 intégrations de sources de données natives, notamment des CRM, des systèmes d’analyse, des bases de données, des plateformes sociales et publicitaires, et se connecte à tous les principaux outils de BI et blocs-notes analytiques.
pour créer un pipeline de données sans ETL dans Panoply, vous devez:
-
sélectionner des sources de données et importer des données: sélectionnez des sources de données dans une liste, entrez vos informations d’identification et définissez des tables de destination. Cliquez sur « collecter » et Panoply extrait automatiquement les données pour vous. Panoply prend automatiquement en charge les schémas, la préparation des données, le nettoyage des données, etc.,
- exécuter des requêtes de transformation: sélectionnez une table et exécutez une requête SQL sur les données brutes. Vous pouvez enregistrer la requête en tant que transformation ou exporter la table résultante au format CSV. Vous pouvez exécuter plusieurs transformations jusqu’à ce que vous obteniez le format de données dont vous avez besoin. Vous ne devriez pas vous soucier de « ruiner” les données – Panoply vous permet d’effectuer toute transformation, mais conserve vos données brutes intactes.
- effectuez l’analyse des données avec les outils de BI: vous pouvez désormais connecter N’importe quel outil de BI tel que Tableau ou Looker à Panoply et explorer les données transformées.,
le processus ci-dessus est agile et flexible, vous permettant de charger rapidement des données, de les transformer en une forme utile et d’effectuer des analyses. Pour plus de détails, voir Mise en route avec Panoply.
avec l’ancien, avec le nouveau
vous connaissez maintenant trois façons de construire un processus de chargement de transformation D’extrait, que vous pouvez considérer comme trois étapes dans l’évolution de L’ETL:
- traitement par lots ETL traditionnel – préparation et transformation méticuleuses des données à l’aide d’un processus rigide et structuré.,
- ETL avec traitement de flux – en utilisant un framework de traitement de flux moderne comme Kafka, vous extrayez des données en temps réel de la source, les manipulez à la volée à l’aide de L’API Stream de Kafka et chargez-les sur un système cible tel Qu’Amazon Redshift.
- pipeline de données automatisé sans ETL-utilisez les pipelines de données automatisés de Panoply pour extraire des données de plusieurs sources, les préparer automatiquement sans nécessiter de processus ETL complet et commencer immédiatement à les analyser à l’aide de vos outils de BI préférés. Commencez avec Panoply en quelques minutes.,
l’ETL traditionnel fonctionne, mais il est lent et devient rapidement obsolète. Si vous souhaitez que votre entreprise maximise la valeur qu’elle extrait de ses données, il est temps de créer un nouveau flux de travail ETL.
Panoply est un endroit sécurisé pour stocker, synchroniser et accéder à toutes vos données d’entreprise. Panoply peut être configuré en quelques minutes, ne nécessite aucune maintenance continue et fournit une assistance en ligne, y compris un accès à des architectes de données expérimentés. Essayez Panoply gratuitement pendant 14 jours.




