¿está atascado en el pasado? ¿Sigue utilizando el lento y anticuado paradigma de extracción, transformación y carga (ETL) para procesar datos? ¿Le gustaría que hubiera métodos más sencillos y más rápidos por ahí?
bueno, ya no deseo! En este artículo, le mostraremos cómo implementar dos de las técnicas de gestión de datos más avanzadas que proporcionan enormes ganancias de tiempo, dinero y eficiencia sobre el modelo tradicional de extracción, transformación y carga.,
uno de estos métodos es el procesamiento de secuencias que le permite tratar datos en tiempo real sobre la marcha. El otro es la gestión automatizada de datos que evita el ETL tradicional y utiliza el paradigma de extracción, carga y transformación (ELT). Para el primero, usaremos Kafka, y para el segundo, usaremos la plataforma de administración de datos de Panoply.
pero primero, vamos a darle un punto de referencia para trabajar con: el proceso de carga de Transformación de extracción convencional y engorroso.
¿qué es ETL (Extract Transform Load)?,
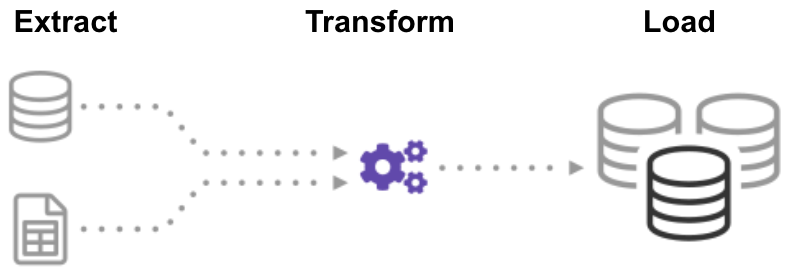
ETL (extraer, transformar, cargar) es un proceso automatizado que toma datos sin procesar, extrae la información necesaria para el análisis, los transforma en un formato que puede satisfacer las necesidades del negocio y los carga en un almacén de datos. Por lo general, ETL resume los datos para reducir su tamaño y mejorar el rendimiento para tipos específicos de análisis.
al crear una infraestructura ETL, primero debe integrar datos de una variedad de fuentes. Luego debe planificar y probar cuidadosamente para asegurarse de transformar los datos correctamente. Este proceso es complicado y requiere mucho tiempo.,
comencemos por ver cómo hacer esto de la manera tradicional: procesamiento por lotes.
crear una canalización ETL con procesamiento por lotes
en una canalización ETL tradicional, procesa datos en lotes desde las bases de datos de origen a un almacén de datos. Es un reto crear un flujo de trabajo ETL empresarial desde cero, por lo que normalmente confía en herramientas ETL como Stitch o Blendo, que simplifican y automatizan gran parte del proceso.,
para crear una canalización ETL con procesamiento por lotes, debe:
- Crear datos de referencia: cree un conjunto de datos que defina el conjunto de valores permitidos que pueden contener sus datos. Por ejemplo, en un campo de datos de país, especifique la lista de códigos de país permitidos.
- extraer datos de diferentes fuentes: la base para el éxito de los siguientes pasos ETL es extraer datos correctamente. Tome datos de una variedad de fuentes, como API, bases de datos no/relacionales, XML, JSON, archivos CSV, y conviértalos en un solo formato para un procesamiento estandarizado.,
- validar datos: Mantenga los datos que tienen valores en los rangos esperados y rechace los que no lo tienen. Por ejemplo, si solo desea fechas del último año, rechace cualquier valor anterior a 12 meses. Analice los registros rechazados, de forma continua, para identificar problemas, corregir los datos de origen y modificar el proceso de extracción para resolver el problema en lotes futuros.
- transformar datos: elimine datos duplicados (limpieza), aplique reglas de negocio, verifique la integridad de los datos (asegúrese de que los datos no se hayan dañado o perdido) y cree agregados según sea necesario., Por ejemplo, si desea analizar los ingresos, puede resumir el monto en dólares de las facturas en un total diario o mensual. Es necesario programar numerosas funciones para transformar los datos automáticamente.
- Stage data: normalmente no carga los datos transformados directamente en el almacén de datos de destino. En su lugar, los datos ingresan primero a una base de datos provisional, lo que facilita la reversión si algo sale mal. En este punto, también puede generar informes de auditoría para el cumplimiento normativo o diagnosticar y reparar problemas de datos.,
- publicar en su almacén de datos: cargar datos en las tablas de destino. Algunos almacenes de datos sobrescriben la información existente cada vez que la canalización ETL carga un nuevo lote; esto puede ocurrir diariamente, semanalmente o mensualmente. En otros casos, el flujo de trabajo ETL puede agregar datos sin sobrescribir, incluida una marca de tiempo para indicar que es nuevo. Debe hacer esto con cuidado para evitar que el almacén de datos «explote» debido al espacio en disco y las limitaciones de rendimiento.,
creación de una canalización ETL con Stream Processing
los procesos de datos modernos a menudo incluyen datos en tiempo real, como datos de análisis web de un gran sitio web de comercio electrónico. En estos casos, no puede extraer y transformar datos en grandes lotes, sino que necesita realizar ETL en flujos de datos. Por lo tanto, a medida que las aplicaciones cliente escriben datos en la fuente de datos, debe limpiarlos y transformarlos mientras están en tránsito al Almacén de datos de destino.
Muchas herramientas de procesamiento de secuencias están disponibles hoy en día, incluidos Apache Samza, Apache Storm y Apache Kafka., El siguiente diagrama ilustra una canalización ETL basada en Kafka, descrita por Confluent:
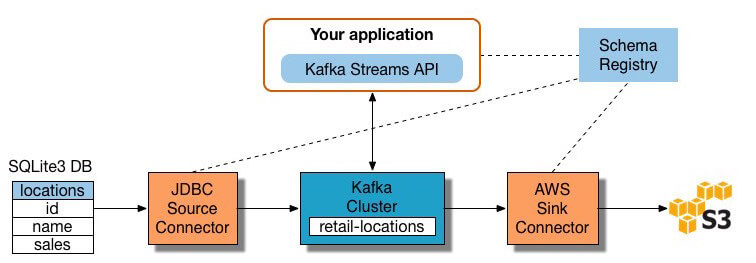
Image Source
para construir una canalización ETL de procesamiento de flujo con Kafka, necesita:
- extraer datos en Kafka: El conector JDBC de Confluent extrae cada fila de la tabla de origen y la Escribe como un par clave/valor en un tema de Kafka (una fuente donde se almacenan y publican los registros). Las aplicaciones interesadas en el estado de esta tabla leen de este tema., A medida que las aplicaciones cliente agregan filas a la tabla de origen, Kafka las Escribe automáticamente como mensajes nuevos en el tema Kafka, lo que habilita un flujo de datos en tiempo real. Tenga en cuenta que puede implementar una conexión de base de datos usted mismo sin el producto comercial de Confluent.
- extraer datos de temas de Kafka: La aplicación ETL extrae mensajes del tema de Kafka como registros Avro, crea un archivo de esquema Avro y los deserializa. Luego crea objetos KStream a partir de los mensajes.,
- transformar datos en objetos KStream: con la API de flujos de Kafka, el procesador de flujos recibe un registro a la vez, lo procesa y produce uno o más registros de salida para los procesadores descendentes. Estos procesadores pueden transformar mensajes uno a la vez, filtrarlos según las condiciones y realizar operaciones de datos en varios mensajes, como la agregación.
- cargar datos a otros sistemas: la aplicación ETL todavía contiene los datos enriquecidos, y ahora necesita transmitirlos a los sistemas de destino, como un Data warehouse o Data lake., En el ejemplo de Confluent, proponen usar su conector de sumidero S3 para transmitir los datos a Amazon S3. También puede integrarse con otros sistemas, como un almacén de datos de Redshift, mediante Amazon Kinesis.
Ahora sabe cómo realizar procesos ETL de la manera tradicional y para transmitir datos. Veamos el proceso que está revolucionando el procesamiento de datos: extraer la transformación de carga.
¿qué es ELT (Extract Load Transform)?,
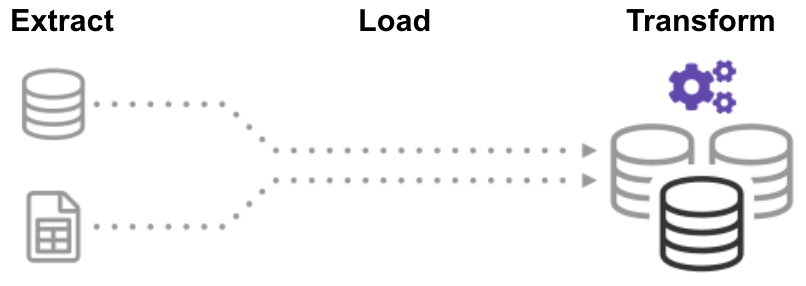
en el proceso Extract Load Transform (ELT), primero extrae los datos y luego los mueve inmediatamente a un repositorio de datos centralizado. Después de eso, los datos se transforman según sea necesario para su uso posterior. Este método pone los datos delante de los analistas mucho más rápido que ETL mientras que simplifica simultáneamente la arquitectura.
Además, el almacén de datos en la nube y la infraestructura de Lago de datos actuales admiten un amplio almacenamiento y una potencia de computación escalable., Por lo tanto, ya no es necesario evitar que el almacén de datos «explote» al mantener los datos pequeños y resumidos a través de transformaciones antes de cargarlos. Es posible mantener grandes grupos de datos en la nube a un bajo costo mientras se aprovechan las herramientas ELT para acelerar y simplificar el procesamiento de datos.
ELT puede sonar demasiado bueno para ser verdad, pero confía en nosotros, ¡no lo es! Construyamos una tubería ELT automatizada ahora.,
construir un Pipeline sin ETL usando un almacén de datos automatizado en la nube
la nueva tecnología de almacén de datos en la nube hace posible lograr el objetivo original de ETL sin construir un sistema ETL en absoluto.
por ejemplo, el almacén de datos en la nube automatizado de Panoply tiene incorporada la gestión de datos de extremo a extremo. Utiliza una arquitectura de auto-optimización, que extrae y transforma automáticamente los datos para que coincidan con los requisitos de análisis., Panoply tiene más de 80 integraciones de fuentes de datos nativas, incluidos CRM, sistemas de análisis, bases de datos, plataformas sociales y publicitarias, y se conecta a todas las principales herramientas de BI y cuadernos analíticos.
para crear una canalización de datos sin ETL en Panoply, debe:
-
seleccionar fuentes de datos e importar datos: seleccione Fuentes de datos de una lista, ingrese sus credenciales y defina tablas de destino. Haga clic en «recopilar» y Panoply extrae automáticamente los datos por usted. Panoply se encarga automáticamente de los esquemas, la preparación de datos, la limpieza de datos y mucho más.,
- ejecutar consultas de transformación: seleccione una tabla y ejecute una consulta SQL contra los datos sin procesar. Puede guardar la consulta como una transformación o exportar la tabla resultante como un CSV. Puede ejecutar varias transformaciones hasta alcanzar el formato de datos que necesita. No debería preocuparse por «arruinar» los datos: la panoplia le permite realizar cualquier transformación, pero mantiene intactos sus datos sin procesar.
- realice análisis de datos con herramientas de BI: ahora puede conectar cualquier herramienta de BI como Tableau o Looker para Panopliar y explorar los datos transformados.,
el proceso anterior es ágil y flexible, lo que le permite cargar datos rápidamente, transformarlos en un formulario útil y realizar análisis. Para obtener más detalles, consulte Introducción a Panoply.
fuera con lo viejo, dentro con lo nuevo
Ahora conoce tres formas de construir un proceso de carga de Transformación de extracto, que puede pensar en tres etapas en la evolución de ETL:
- procesamiento por lotes ETL tradicional: preparación y transformación de datos meticulosamente utilizando un proceso rígido y estructurado.,
- ETL con procesamiento de secuencias: con un marco de procesamiento de secuencias moderno como Kafka, extrae datos en tiempo real del origen, los manipula sobre la marcha utilizando la API de secuencias de Kafka y los carga en un sistema de destino como Amazon Redshift.
- canalización de datos automatizada sin ETL: utilice las canalizaciones de datos automatizadas de Panoply para extraer datos de múltiples fuentes, prepararlos automáticamente sin requerir un proceso ETL completo e inmediatamente comenzar a analizarlos utilizando sus herramientas de BI favoritas. Comience con Panoply en minutos.,
El ETL tradicional funciona, pero es lento y rápido quedando obsoleto. Si desea que su empresa maximice el valor que extrae de sus datos, es hora de un nuevo flujo de trabajo ETL.
Panoply es un lugar seguro para almacenar, sincronizar y acceder a todos los datos de su empresa. Panoply se puede configurar en minutos, no requiere mantenimiento continuo y proporciona soporte en línea, incluido el acceso a arquitectos de datos experimentados. Prueba Panoply gratis durante 14 días.




